
The Infrastructure Layer for Programming Biology
Indexing Life

When 23andMe launched, it had the chance to become biology’s Bloomberg Terminal. A consumer brand with distribution, vision, and consented genomic data from over 12 million people. But it squandered the opportunity. Instead of building infrastructure, it stayed in consumer novelty. It’s a lesson: in biotech, data is not oil, it’s a supply chain.
If biology is to be programmable, it needs more than genomes. It needs systems. Context-rich, longitudinal, interoperable systems that plug into the mechanics of discovery and care. That requires infrastructure. It also requires a new class of companies: data brokers for biology. These companies collect, structure, and distribute biological data like a utility, not a silo.
Biology as a Stack, Not a Snapshot
The genome tells you inherited risk. RNA shows transcriptional state. Proteins reflect function and therapeutic targets. Metabolites hint at real-time cellular processes. Link these modalities to phenotype and outcomes and you don’t just describe disease, you compute it.
This is what the Central Dogma becomes in the data age: a multilayered biological dataset. But without clinical context, it collapses. A genome without an EHR is a string of letters. A proteome without outcomes is noise.
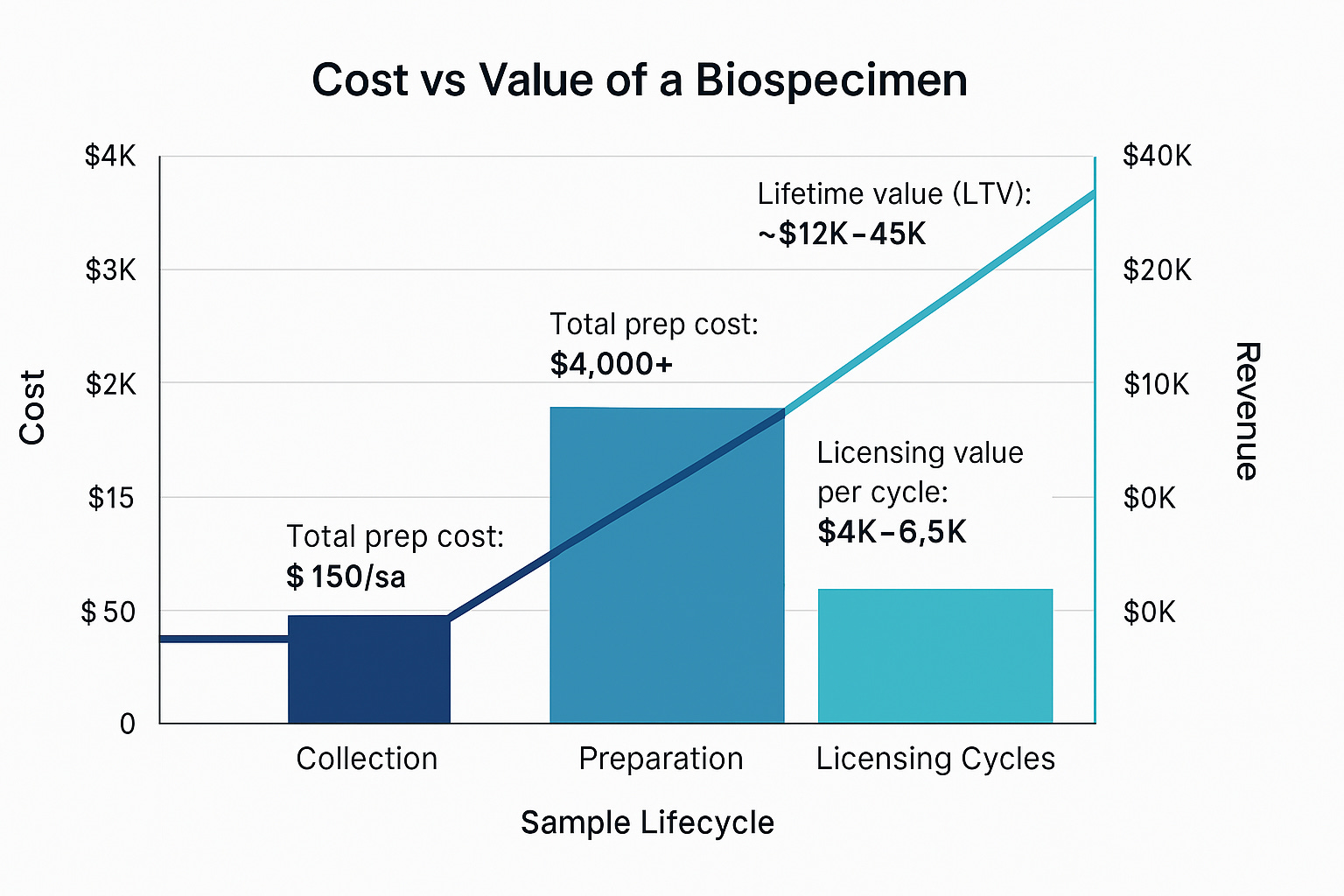
Fully characterized samples, whole genome sequenced, linked to electronic health records, consented, and followed longitudinally, cost between $1,000 and $4,500 depending on sequencing depth, abstraction quality, and compliance infrastructure. These are the atomic units of programmable biology.

Biobanks Are Becoming Data Engines
The biobank of the past was a vault. A static archive of frozen samples and paperwork. But the biobank of the present, and the future, is alive. It’s a dynamic engine of clinical, molecular, and longitudinal data linked to outcomes and fed into decision systems.
Take Tempus. By integrating oncology diagnostics, patient testing, and real-world data capture, it’s turned biospecimens into a high-margin data product. Half of its revenue now comes from B2B data partnerships. Caris Life Sciences, similarly, has raised over $1B to operationalize molecular profiling at scale, feeding that data into both diagnostics and licensing arms.
Even public-sector projects like NIH’s All of Us and UK Biobank have evolved. No longer just repositories, they are now developer platforms for biology. With over 500,000 consented participants, All of Us links biospecimens to EHRs, surveys, and wearables. UK Biobank has powered thousands of studies, enabling everything from cardiovascular polygenic risk scoring to drug repurposing models.
But there’s friction. Although the cost to acquire a biospecimen can be as low as $150, the infrastructure to make it usable — sequencing, data abstraction, consent validation — can push total costs north of $4,000. Only 38 percent of stored biospecimens are ever accessed. And yet, fully monetized, each one can generate upwards of $10,000 in licensing value across multiple research cycles.
The bottleneck isn’t sample collection. It’s activation. The challenge and opportunity is to build better interfaces that make biospecimens as queryable as cloud data.
The Emergence of Biological Data Brokers
The parallel to tech is clear. As consumer internet platforms scaled in the 2000s, data brokers emerged to unify fragmented datasets, enable personalization, and sell structured insights. Now, that model is being translated to biology.
But instead of clicks and purchase intent, the raw material is whole genomes, EHRs, pathology reports, and real-world evidence. The product isn’t ad-targeting. It’s biomarkers, synthetic controls, and trainable clinical predictors.
Bioptimus is building one of the first foundation models trained on structured biological datasets. Its early architecture centers on protein-ligand interactions, geared toward de novo therapeutic design. Think of it as a vertically integrated transformer stack for life sciences.
Data Lake is attacking the consent and governance layer. Rather than scrape or license from third parties, it’s building a GDPR-compliant, patient-directed data donation system across Europe. With over 380,000 structured records, its focus is on consent granularity and auditability, which is key for future EU regulatory harmonization.
Weavechain addresses the transfer and privacy challenge. Its architecture uses zero-knowledge proofs to enable hospital networks to share clinical data without full offloading. The result is lower cost, greater auditability, and tokenized consent pathways.
Hyper Unison plays a different role: it curates massive-scale genomic datasets pre-linked to treatment outcomes. This makes it particularly attractive for pharma doing early-stage target validation. It’s already working with 17 of the top 20 drugmakers, charging per-query licensing fees.
Sano Genetics offers another route. Rather than start with enterprise health systems, it begins with individuals by offering free genetic testing and then compensating users for contributing their data to research. With a 78 percent opt-in rate, it’s one of the most efficient engines for building consented longitudinal cohorts.
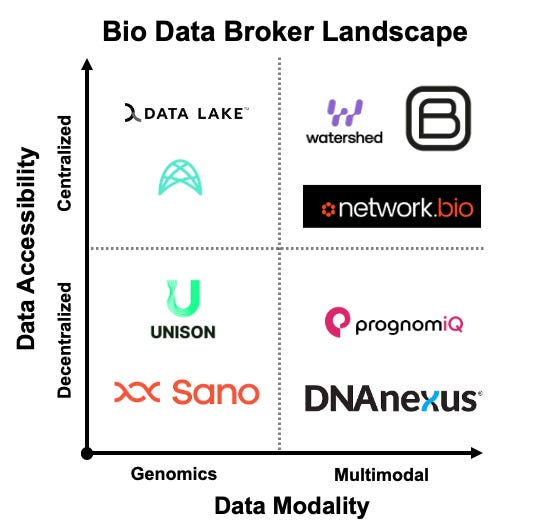
What ties these players together is not a shared modality but a shared insight: structure beats scale. Data is only valuable to the extent it is findable, usable, interoperable, and permissioned. Those that build with that in mind are creating the scaffolding of programmable biology.
From Model Training to Trial Acceleration
The impact of structured, multimodal biological data is becoming concrete. AI-native biotech companies are reshaping the way we approach drug development by using biological data not just for hypothesis generation but for experimental simulation. Recursion generates millions of phenotypic images per week, feeding a machine-learning pipeline that predicts compound efficacy before in vivo work even begins. Exscientia builds AI-driven drug discovery engines tied to stratified patient data, optimizing drug design with anticipated responder profiles. Insitro leverages real-world clinical and molecular data to train causal models of disease and therapeutic response.
On the clinical side, structured EHR and omics data are accelerating trial recruitment. Eligibility criteria that once required manual chart reviews are now modeled algorithmically to flag ideal candidates. Synthetic control arms, built from historical or observational datasets, are being used to supplement or even replace traditional comparators. Their concordance with RCTs in certain settings, particularly in oncology, is already informing regulatory guidance.
Beyond enrollment, these data systems improve trial outcomes. Adaptive designs allow for earlier stopping, mid-trial cohort expansion, or biomarker-based re-randomization. The underlying data infrastructure becomes not just an operational asset but a competitive advantage reducing cost per patient, increasing statistical power, and compressing timelines.
This marks a shift in how trials are engineered. They’re no longer just executed. They’re modeled, iterated, and optimized, using biological data as a dynamic substrate.
Technical Debt, Market Friction
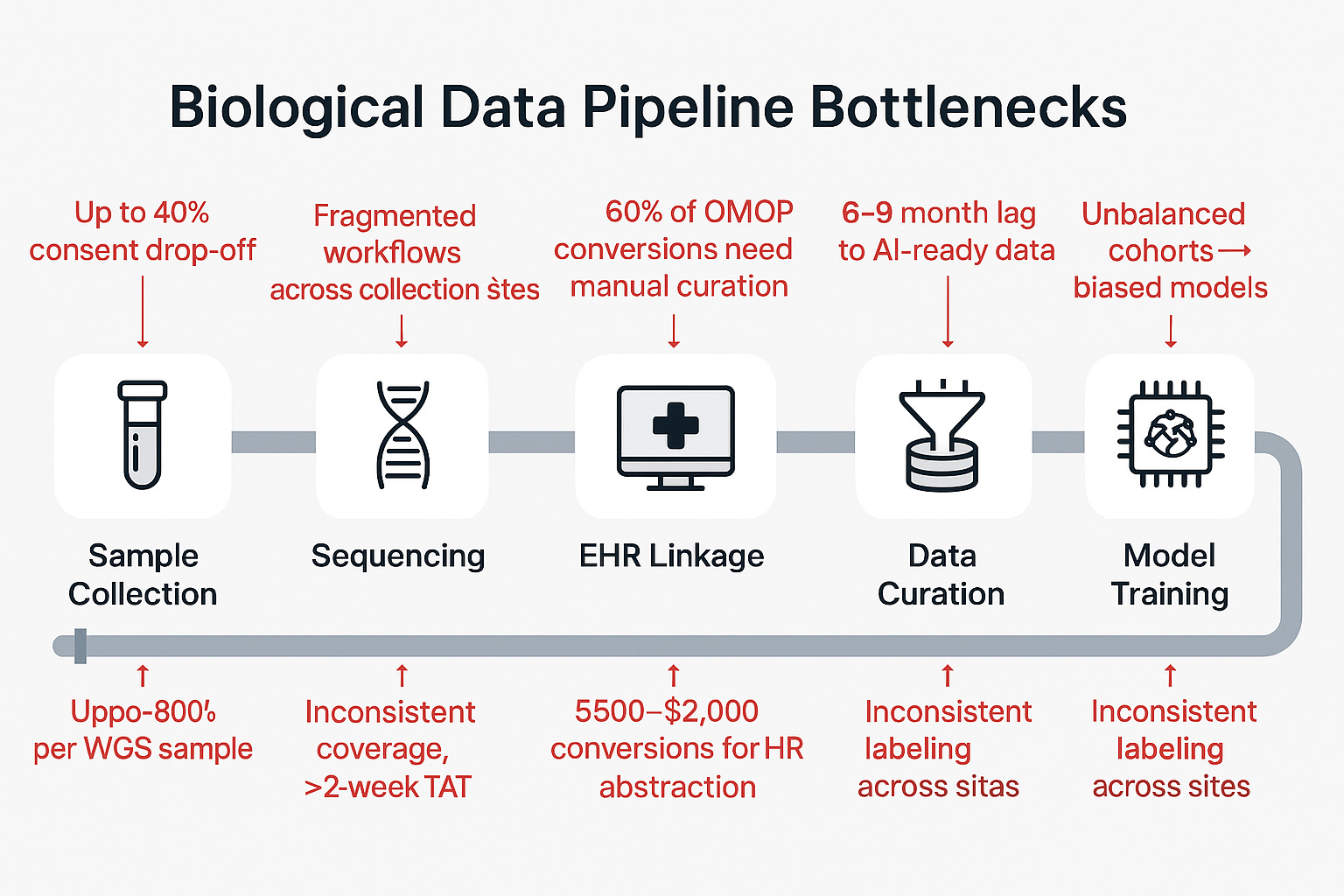
Despite the progress, the system is held back by foundational debt. The majority of hospital systems still operate on legacy EHR architectures that are incompatible with modern interoperability standards. Only a small fraction of institutions support FHIR 4.0. OMOP conversions, used to standardize datasets across providers, often require manual curation.
Even once a sample is collected, delays abound. It can take 6 to 9 months to convert a biospecimen into a structured, analysis-ready data object. GDPR compliance adds up to 20% in operational overhead for companies working with European data. Storage remains a cost center ranging from $20 to $40 per TB per month for compliant infrastructure. A data breach in a biobank setting can cost an average of $4.4 million, making security non-negotiable.
These aren’t niche problems. They are the daily reality of data infrastructure in biotech. Solving them is what will separate point solutions from platform businesses.
What Builds a Moat in Biological Data
It isn’t just sequencing. It’s structured access. It’s data with consent, context, and clinical endpoints. What differentiates the next generation of infrastructure companies will be:
Distribution: Partnerships with hospitals, CROs, and payers
Composability: Ability to link and layer data types cleanly
Feedback Loops: Data that trains models, which improve care, which creates more data
What’s becoming clear is that the next stage of biotech innovation won’t come from more discovery alone, but from better orchestration. The companies that succeed will be those that standardize how biological data flows across hospitals, labs, and models and how it’s used, reused, and trusted.
Rather than a single platform or business model, the winners will be those who build infrastructure that others can build upon: storage that supports auditability, consent systems that scale across jurisdictions, and data models that plug into AI-native workflows. This isn’t a data land grab. It’s a systems design problem.
The companies that solve it will enable more precise clinical trials, faster therapeutic development, and smarter diagnostics, not through scientific novelty, but through biological clarity.
If you’re building or investing in any layer of this stack—data infrastructure, biological modeling, or AI-driven trial design — reach out.